


ChatGPT için Gerçek Dünyadan Beş Mühendislik Zorluğu
✏️ Lansmanından sadece bir yıl sonra ChatGPT'nin haftalık 100 milyondan fazla kullanıcısı oldu. Bu patlayıcı talebi karşılamak için OpenAI ekibi çeşitli ölçeklendirme zorluklarının üstesinden gelmek zorunda kaldı. Özel bir derinlemesine inceleme.
Kasım 2022'de ChatGPT, uygulamalı Yapay Zeka (AI) için şimdiye kadarki en büyük "vay canına!" anı ve bugün teknolojiye devam eden yatırım artışının katalizörü olduğunu söylemek güvenli bir şekilde dünyayı kasıp kavurdu. CEO Sam Altman, ürünün Kasım 2023'te haftalık 100 milyon kullanıcıya ulaşacağını duyurdu: bu, bu alanda bile benzeri görülmemiş bir büyüme.
Daha önce OpenAI ve ChatGPT ekibinin nasıl bu kadar hızlı sevkiyat yaptığını ele almıştık. O makalede, organizasyonun kurulumunu, Uygulamalı ekibin Araştırma ile entegrasyonunu, ayrılmamış ve artımlı sürümler stratejisini ve daha fazlasını inceledik.
Peki ya patlayıcı büyümenin getirdiği gerçek ölçeklendirme zorlukları ne olacak? Daha fazla bilgi edinmek için, ChatGPT'nin lansmanı ve ölçeklendirilmesi sırasında Applied mühendislik ekibine liderlik eden Evan Morikawa'ya tekrar başvurdum.
Bugün Evan, mühendislik zorluklarını ve ekibin bunlarla nasıl başa çıktığını açıklıyor. Bu konuyu ele alıyoruz:
OpenAI hakkında bilgi tazeleme ve Evan'a giriş
GPU'ların Önemi
ChatGPT4 nasıl çalışır?
Beş ölçeklendirme zorluğu:
KV Önbellek ve GPU RAM
Parti boyutunu optimize etme
Ölçmek için doğru metrikleri bulma
Nerede olurlarsa olsunlar GPU'ları bulma
Otomatik ölçeklendirememe
Çıkarılan dersler
Bununla birlikte, Evan'a geçti.
1. OpenAI ve Evan hakkında bir tazeleme
OpenAI'ye nasıl katıldınız ve ChatGPT'yi de oluşturan Uygulamalı mühendislik grubunun başına geçtiniz?
OpenAI, şirketin ürünlerinden sadece biri olan ChatGPT'nin yaratıcısıdır. Gönderilen diğer ürünler arasında DALL-E 3 (görüntü oluşturma), GPT-4 (gelişmiş bir model) ve geliştiricilerin ve şirketlerin yapay zekayı süreçlerine entegre etmek için kullandıkları OpenAI API yer alıyor. ChatGPT ve API'nin her biri birkaç model sınıfını ortaya çıkarır: GPT-3, GPT-3.5 ve GPT-4.
Bu ürünleri üreten ve ölçeklendiren mühendislik, ürün ve tasarım organizasyonu "Applied" olarak adlandırılıyor ve GPT-3'ün piyasaya sürüldüğü 2020 yılında kuruldu. OpenAI'nin araştırmalarını güvenli bir şekilde dünyaya sunmakla görevlendirilmiştir. OpenAI'nin kendisi 2015 yılında kuruldu ve bugün şirketin özünde hala güvenli ve uyumlu bir yapay genel zeka (AGI) yaratma hedefine sahip bir araştırma laboratuvarı var.
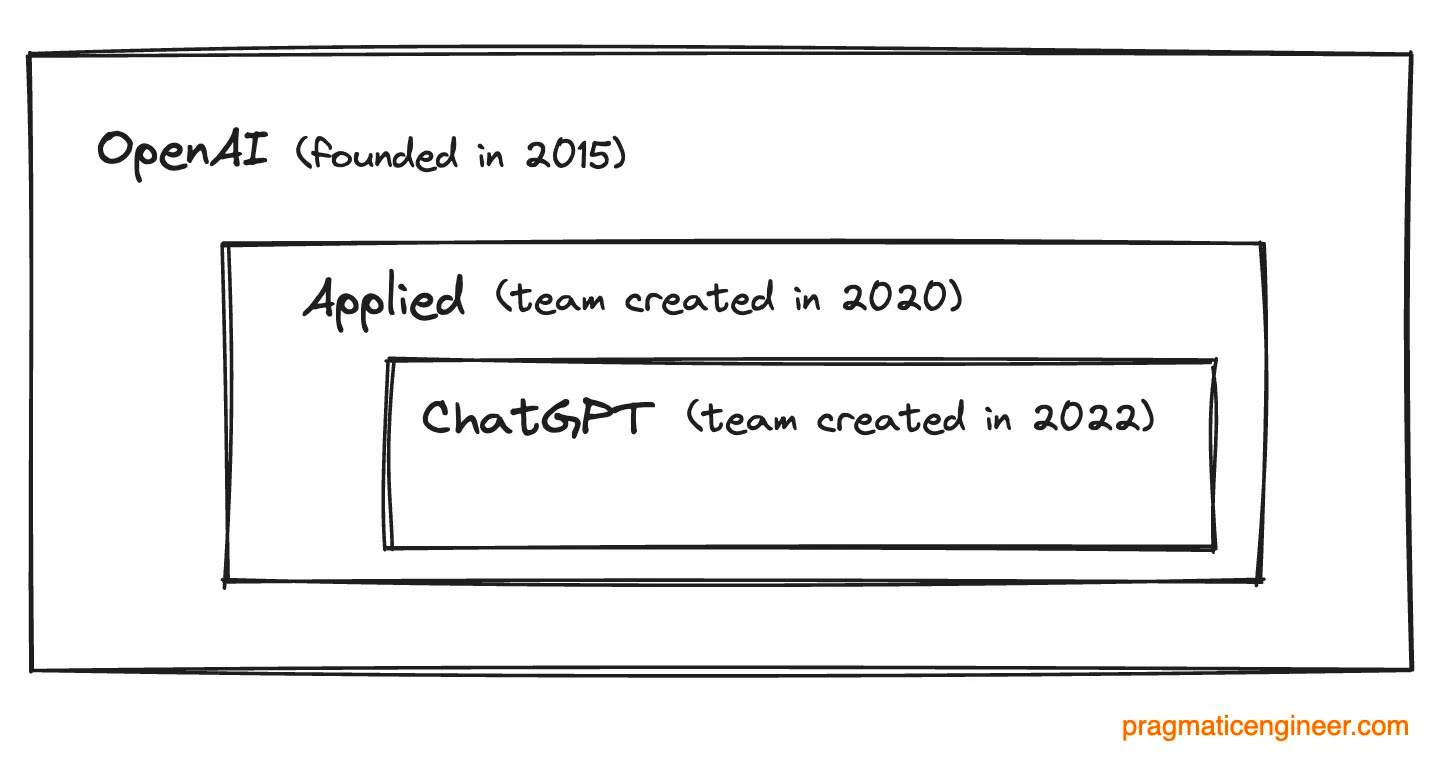
OpenAI'ye Ekim 2020'de Applied henüz çok yeniyken katıldım. Makine Öğrenimi alanında doktoram yoktu ve API'ler ve mühendislik ekipleri oluşturma fikri beni heyecanlandırmıştı. İlk günlerinden ChatGPT'nin lansmanı ve ölçeklendirilmesine kadar tüm Uygulamalı Mühendislik kuruluşumuzu yönettim. Evan'ın hikayesi hakkında daha fazla bilgiyi Inside OpenAI'da bulabilirsiniz: ChatGPT nasıl bu kadar hızlı gönderildi?
2. ChatGPT nasıl çalışır? Bir tazeleme.
Son birkaç yılını ChatGPT'yi sıfırdan inşa ederek geçirmemiş olanlarımız için, bu nasıl çalışıyor?
Bazı ölçeklendirme konularını tanıtmak için, bu AI modellerinin nasıl çalıştığı hakkında hızlı bir giriş yapmama izin verin. Temel bilgilere aşinaysanız 3. bölüme geçebilirsiniz.
ChatGPT'ye bir soru sorduğunuzda birkaç adım gerçekleşir:
Giriş. Metin girişinden metninizi alırız.
Tokenizasyon. Bunu belirteçlere ayırırız. Bir token kabaca birkaç unicode karakterine eşlenir. Bunu bir kelime olarak düşünebilirsiniz.
Yerleştirmeler oluşturun. Her bir belirteci sayılardan oluşan bir vektöre dönüştürürüz. Bunlara gömme adı verilir.
Katıştırmaları model ağırlıkları ile çarpın. Daha sonra bu katıştırmaları yüz milyarlarca model ağırlığıyla çarpıyoruz.
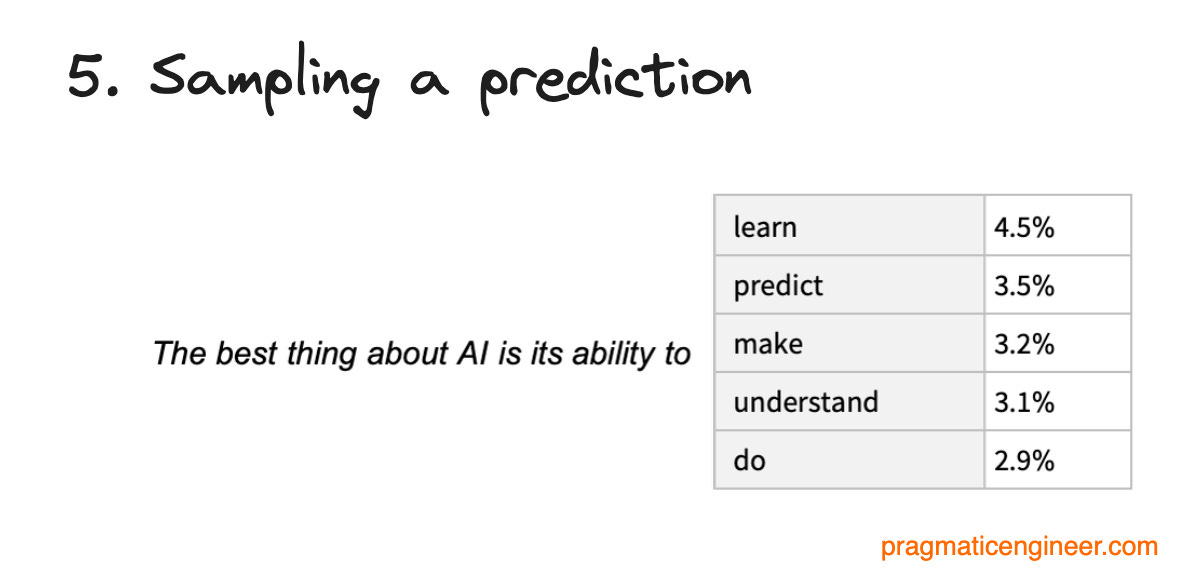
Bir tahmini örnekleyin. Bu çarpma işleminin sonunda, sayı vektörü bir sonraki en olası belirtecin olasılığını temsil eder. Bu bir sonraki en olası belirteç, ChatGPT'den çıkan bir sonraki birkaç karakterdir.
Bu adımları görselleştirelim. İlk ikisi basittir:

Belirteçleştirmenin mutlaka metni kelimelere bölmek anlamına gelmediğini unutmayın; belirteçler kelimelerin alt kümeleri de olabilir.
Gömüler, büyük dil modellerinin (LLM) kalbinde yer alır ve bir sonraki adımda bunları belirteçlerden oluşturuyoruz:

Gömme, bir belirtecin çok boyutlu bir gösterimidir. Bazı modellerimizi, kelimeler veya kelime öbekleri arasındaki anlamsal anlamların ve ilişkilerin yakalanmasına açıkça izin verecek şekilde eğitiyoruz. Örneğin, "köpek" ve "köpek yavrusu" sözcüklerinin katıştırması, "köpek" ve "bilgisayar" sözcüklerinin katıştırmasına kıyasla birçok boyutta birbirine daha yakındır. Bu çok boyutlu katıştırmalar makinelerin insan dilini daha verimli bir şekilde anlamasına yardımcı olur.
Model ağırlıkları, bir sonraki olası belirteci tahmin etmek için kullanılan ağırlıklı bir gömme matrisini hesaplamak için kullanılır. Bu adım için OpenAI'nin yüz milyarlarca ağırlıktan oluşan ağırlık matrisini kullanmamız ve bunu katıştırmalardan oluşturduğumuz bir matrisle çarpmamız gerekiyor. Bu yoğun hesaplama gerektiren bir çarpımdır.

Bir tahminin örneklenmesi milyarlarca çarpma işlemi yapıldıktan sonra gerçekleştirilir. Son vektör, bir sonraki en olası belirtecin olasılığını temsil eder. Örnekleme, bir sonraki en olası belirteci seçtiğimiz ve kullanıcıya geri gönderdiğimiz zamandır. ChatGPT'den çıkan her kelime, saniyede birçok kez tekrarlanan bu aynı işlemdir.
Ön eğitim ve çıkarım
Değerleri insan bilgisinin çoğunu kodlayan bu karmaşık model ağırlıkları kümesini nasıl oluşturuyoruz? Bunu ön eğitim adı verilen bir süreçle yapıyoruz. Amaç, internetteki tüm kelimeler için bir sonraki belirteci (kelime olarak düşünebilirsiniz) tahmin edebilecek bir model oluşturmaktır.
Ön eğitim sırasında ağırlıklar, matematiksel bir optimizasyon yöntemi olan gradyan inişi yoluyla kademeli olarak güncellenir. Gradyan inişinin bir benzetmesi, bir dağda sıkışmış ve aşağı inmeye çalışan bir yürüyüşçüdür. Ancak, görüşlerini çevrelerindeki küçük bir alanla sınırlayan yoğun sis nedeniyle dağı tam olarak göremezler. Eğimli iniş, yürüyüşçünün mevcut konumundan eğimin dikliğine bakmak ve en dik iniş yönünde ilerlemek anlamına gelir. Dikliğin basit bir gözlemle anlaşılamayacağını varsayabiliriz, ancak neyse ki bu yürüyüşçünün dikliği ölçmek için bir aleti var. Ancak, tek bir ölçüm yapmak zaman alır ve gün batımından önce aşağı inmek isterler. Dolayısıyla, bu yürüyüşçünün ne sıklıkta durup dikliği ölçeceğine karar vermesi gerekiyor ki gün batımından önce inebilsin.
Modelimizi oluşturduktan sonra üzerinde çıkarım yapabiliriz, bu da modeli metinle yönlendirdiğimiz zamandır. Örneğin, istem şöyle olabilir: "Pragmatik Mühendis için bir konuk yazı yazın." Bu istem daha sonra modelden bir sonraki en olası belirteci (kelimeyi) tahmin etmesini ister. Bu tahmini geçmiş girdilere dayanarak yapar ve bu işlem, yazınızı ortaya çıkarana kadar tekrar tekrar, belirteç belirte, kelime kelime gerçekleşir!
Gergely'den not: sadece söylemek için, bu yazı veya yayınladığım diğer yazılar ChatGPT tarafından yapılmadı! Ancak teknolojinin nasıl çalıştığını öğrenmek için eğlenceli bir deney. İşte ChatGPT'nin bu komuta yanıt olarak her zaman bir sonraki en olası belirteci (kelimeyi) oluşturarak ürettiği şey. Bu tahmin tekniği hakkında daha fazla ayrıntı için Stehen Wolfram tarafından yazılan ChatGPT ne yapıyor ve neden çalışıyor?
Kendi kendine dikkatten kaynaklanan ölçeklenebilirlik sorunu
Kaputun altında, Transformer mimarisini kullanıyoruz, bu mimarinin temel özelliği her bir tokenin diğer tüm tokenlerden haberdar olmasıdır. Bu yaklaşım öz dikkat olarak bilinir. Bunun bir sonucu olarak, metniniz ne kadar uzunsa - veya bağlam - o kadar fazla matematik gerekir.
Ne yazık ki, öz dikkat karesel olarak ölçeklenir. Modelin 100. belirteci tahmin etmesini istiyorsanız, yaklaşık 10.000 işlem yapması gerekir. Modelin 1.000. belirteci tahmin etmesini istiyorsanız, yaklaşık 1 milyon işlem yapması gerekir.
İlk başta bu kulağa kötü bir haber gibi geliyor. Ancak, ikinci dereceden ölçek sorununu aşmak için kullanabileceğimiz akıllıca geçici çözümler vardır. Bu sorunu nasıl çözeceğimize geçmeden önce, ChatGPT'ye güç veren altyapı hakkında konuşmamız gerekiyor.
3. GPU'ların Önemi
GPU'lar (Grafik İşleme Birimleri) ChatGPT'nin ve üzerine inşa edildiği API'lerin can damarıdır. GPU'ların son derece az tedarik edilmesi, tuhaflıkları ve maliyetleri, çalışma ve ölçeklendirme şeklimizi belirliyor.
Sahneyi hazırlamak için, size kullandığımız GPU'lardan birini tanıtmama izin verin.

Bu NVIDIA H100'dür. Her GPU'ya bağlı özel bir Yüksek Bant Genişlikli Bellek (HBM) belleği vardır. GPU'lar birbirleriyle NVLink adı verilen yüksek bant genişlikli bir ara bağlantı ile konuşabilir ve Infiniband adı verilen özel bir ethernet alternatifiyle dış dünyayla konuşabilirler. Bunlardan 8 tanesini tek bir düğümde topluyoruz. Nvidia, DGX H100 adında benzer bir yapılandırma satıyor.
Bizim için, eklenen her işlem veya bant genişliği ChatGPT kullanıcı deneyimini doğrudan etkiliyor.
4. Beş ölçeklendirme zorluğu
GPU'ların ölçeklendirme zorlukları hakkında konuşulacak çok şey var. Biz odaklanıyoruz:
#1: GPU RAM ve KV Önbellek
#2: Toplu iş boyutu, ops:bayt ve aritmetik yoğunluk
#3: Ölçmek için doğru metrikler
#4: Nerede olurlarsa olsunlar GPU'ları bulma
#5: Otomatik ölçeklendirme; eksikliği
ChatGPT'yi ölçeklendirirken bunları anlamak çok önemliydi. Hadi onlara girelim!
Zorluk #1: KV önbelleği ve GPU RAM'i
En büyük zorluğumuz, öz dikkatin dört kat ölçeklenmesi, yani ne kadar çok jeton üretirsek, dört kat daha fazla işleme ihtiyacımız olmasıdır (100. jeton için yaklaşık ~10.000 işlem, ancak 1.000. jeton için yaklaşık 1.000.000 işlem). Performansı nasıl artırabiliriz?
İlk geçici çözüm, önceki tüm belirteçler için yaptığımız matematiği önbelleğe almaktır; KV önbelleği. Makine öğrenimi (ML) modelimizde dikkat mekanizmasını kullanıyoruz. Bu modelde üç vektör kullanıyoruz:
Q: neyi dahil ettiğimizle ilgili
K: çıktıya girdi olarak ne kullandığımızla ilgili
V: öğrenilen vektör; hesaplamaların çıktısı
Hem K hem de V'yi önbelleğe alabiliriz, dolayısıyla "KV önbellek" adını alır. Ancak Q'yu önbelleğe alamayız çünkü bu vektör her seferinde değişir.
KV Önbelleğini GPU RAM'inde saklamamız gerekiyor. Bunun nedeni, Yüksek Bant Genişlikli Bellek (HBM) kullandığımızda GPU RAM'de veri taşımanın yaklaşık 3TB/sn hıza sahip olmasıdır. Ancak, verileri bir PCIe veri yolu (PCI Express: veri aktarımı için anakartlarda yaygın olarak kullanılan yüksek hızlı bir veri yolu standardı) üzerinden itersek yaklaşık 30GB/sn hız elde ederiz. HBM kullanmak PCIe'den yaklaşık iki kat daha hızlıdır (yaklaşık 100 kat)!
HBM neden bu kadar hızlı? Fiziksel olarak yığılmış katmanlar halinde GPU'lara bağlanmıştır ve büyük ölçüde paralel veri çıkışı için binlerce pine sahiptir.
Bu GPU HBM RAM'i çok pahalı ve oldukça sınırlıdır. HBM RAM'in çoğu da model ağırlıklarını tutmak için harcanıyor. Her önbellekte olduğu gibi, dolduğunda en eski verilerin "süresini doldurarak" yer açarız.
"Önbellek ıskalamaları" bizim kullanım durumumuz için pahalıdır. Bir önbellek ıskası, hesaplamamız için gereken önbelleğe alınmış bir değerin bulunamamasıdır; tipik olarak bu değerin "süresini doldurmamız" ve yer açmak için HBM belleğimizden atmamız gerekir. Eğer bir önbellek ıskası varsa, bütün bir ChatGPT konuşmasını yeniden hesaplamamız gerekir! Ve şu anda 1.000. karakterdeyiz, yani bu 1 milyon işleme yakın olabilir!
Altyapımız GPU RAM'i kullanıcılar arasında paylaştırıyor. Bunun anlamı, bir kullanıcı olarak konuşmanız çok uzun süre boşta kalırsa, diğer konuşmalar için yer açmamız gerektiğinden sistemden (GPU önbelleğinden) çıkarılabileceğidir.
Bu önbellekleme yaklaşımının çeşitli sonuçları vardır:
GPU RAM'i çok değerli bir maldır. Pratikte, LLM işlemleri için en sık karşılaşılan darboğaz işlem kaynağı değil GPU RAM'idir.
Önbellek ıskalama oranları çok önemlidir! Önbellek ıskalama, sistemin önbellekten - KV önbelleği gibi - veri almaya çalıştığı ancak hiçbir şeyin önbelleğe alınmadığı olayları ifade eder. Önbellek ıskalamaları, GPU'ların ne kadar iş yaptığı üzerinde büyük ve doğrusal olmayan bir etkiye sahiptir. Önbellek ıskalama oranı ne kadar yüksekse, GPU'ların doğrusal olarak değil, karesel olarak daha fazla çalışması gerekir.
Bu da ChatGPT'yi ölçeklendirirken bakılacak basit bir CPU kullanım metriği olmadığı anlamına geliyor. KV Önbellek kullanımına ve GPU RAM'ini nasıl en üst düzeye çıkaracağımıza bakmamız gerekiyordu.
Zorluk #2: Parti boyutunu optimize etme
Toplu iş boyutu, ChatGPT'yi ölçeklendirirken dengelenmesi gereken ikinci bir metriktir. Kabaca ifade etmek gerekirse, toplu iş boyutu bir GPU üzerinden çalıştırdığımız eşzamanlı isteklerin sayısıdır.
Bir H100 GPU, kayıtlarına saniyede en fazla 3,35 TB RAM taşıyabilir. GPU yazmaçları, bilgi işlem çekirdeğinin daha sonra yürüteceği işlemler için işlenenleri depolayan hızlı çip üstü belleklerdir.
Verilerin yazmaçlara taşındığı aynı saniye içinde H100, 1,98 katrilyon 8 bit kayan nokta sayısını çarpabilir. Bu 1,98 katrilyon işlemi taşınan 3,35 TB veriye bölelim; H100, 1 baytı taşımak için gereken sürede 591 kayan nokta işlemi yapabilir.
H100 591:1 işlem:bayt oranına sahiptir. Eğer 1GB'ı taşımak için zaman harcayacaksanız, saniyede en az 591 milyar kayan nokta işlemi (FLOP) yapmalısınız. Bundan daha azını yapmak GPU FLOP'larını boşa harcamak anlamına gelir. Ancak, daha fazlasını yaparsanız, bellek bant genişliğini beklersiniz.
Modellerimizde, hareket ettirdiğimiz bellek miktarı kabaca model ağırlıklarımızın boyutunda nispeten sabittir.
İlgili matematiksel hesaplamaların hacmini değiştiren toplu iş boyutumuzu ayarlayarak süreç üzerinde biraz kontrol sahibi oluyoruz.
ChatGPT'yi ölçeklendirirken, GPU'ları tamamen "doyurmamız" gerekiyordu, yani doğru FLOPS'a sahip olmak için toplu iş boyutlarımızı izlememiz gerekiyordu, böylece GPU'lar hesaplama için yetersiz kullanılmıyordu, ancak aynı zamanda bellek bant genişliğini bekleyecek şekilde aşırı kullanılmıyordu.
Gerçekte, kutu üzerinde yazılı flop sayılarını gerçekten sürdürmek imkansızdır. Yaklaşmak için matematiği kullanabiliriz, ancak her şeyin ince ayarını yapmak için prod'da çok sayıda deney yapılması gerekiyordu.
Zorluk #3: Ölçmek için doğru metrikler
Toplu iş boyutu ve KV önbellek kullanımı kombinasyonu odaklandığımız birincil metrikti. Bunlar sunucularımızın ne kadar yüklü olduğunu belirlemek için kullandığımız iki sayıdır. Bu metriğe başlangıçta ulaşmadık; bizim için en iyi sonucu verdiğini anlamamız zaman aldı.
Başlangıçta, standart cpu kullanım metriklerine benzer daha basit bir gpu kullanım metriğimiz vardı. Ancak, basit kullanım yalnızca gpu'nun bir zaman diliminde matematik yapıp yapmadığını söylediği için yanıltıcı olduğu ortaya çıktı. Bize bir şey söylemedi:
Doygun aritmetik yoğunluğumuz olup olmadığını; kayan nokta işlemlerinin toplam veri hareketine oranı: FLOPs/byte. Temel olarak, GPU kullanımı bize hesaplamayı az kullanıp kullanmadığımızı veya bellek açlığı çekip çekmediğimizi söylemiyordu.
KV önbelleğinin tükenip tükenmediğini. Bu bir sorundur çünkü KV önbelleği kaçırıldığında, GPU'nun önbelleğe alınmamış sonuçları hesaplamak için dört kat daha fazla hesaplama yapması gerekir.
Diğer darboğazlar da var. KV önbelleği ve yığın boyutu bulduğumuz tek darboğazlar değildi. Gerçek dünyada şu darboğazlarla karşılaştık:
Bellek bant genişliği
GPU'lar arasında ağ bant genişliği
Düğümler (makineler) arasındaki ağ bant genişliği
...sadece üç tanesini saymak gerekirse!
İşi daha da karmaşık hale getirmek için, darboğazların yerleri sık sık değişir. Örneğin, ChatGPT'den bir makaleyi özetlemesini istemek, ondan bir makale yazmasını istemekten çok farklı performans özelliklerine sahiptir. LLM dönüştürücü model mimarisindeki belirli ayrıntıları sürekli olarak değiştiriyoruz ve bu değişiklikler darboğazların nerede meydana geldiğini etkiliyor.
LLM'lerin problem uzayında karşılaştığınız kısıtlamalarda beklenmedik derecede geniş bir değişkenlik var. Bu da bizim çözmemizi ve çip üreticilerinin optimum dengeyi sağlayan çipler tasarlamasını zorlaştırıyor.
Örneğin, NVidia'nın yeni H100 çipi, A100 çipinden sonraki nesildir. H100, bellek boyutu sabit kalırken ve bellek bant genişliği yalnızca 1,6 kat artarken, işlem hacmini (diğer bir deyişle FLOP'ları) yaklaşık 6 kat artırıyor. Sıklıkla bellek tarafından darboğaza sokulduğumuz için, FLOP'lardaki (ve maliyetteki) dramatik artış atıl kalma eğilimindedir.
Gerçek şu ki, bugün NVIDIA H100 gibi en üst düzey bir çipin tasarımı yıllar öncesine dayanıyor. Gelecekteki mimarileri tahmin etmek zor olduğundan, NVIDIA'nın H100 çipi tasarlandığında belleğin önemine ilişkin keşifleri bilmesinin bir yolu yoktu. Kısa süre önce duyurulan H200 çipi daha fazla belleğe sahiptir; ancak sektörün LLM'leri geniş ölçekte çalıştırmak için bu benzersiz darboğazları daha iyi anlaması biraz zaman aldı.
Zorluk #4: GPU'ları nerede olurlarsa olsunlar bulmak
GPU'larla ilgili bir başka zorluk da onları nereden bulacağımızdı! Şirketimiz - ve genel olarak yapay zeka alanı - NVIDIA gibi tedarikçilerin veya TSMC tedarik zincirinin tamamının GPU üretebileceğinden çok daha hızlı büyüdü. Yarı iletkenler ve veri merkezleri gibi karmaşık bir tedarik zincirinde birçok yerde darboğazlar yaşanır.
Çözümlerden biri GPU'ları mümkün olan her yerden temin etmekti. Bulut sağlayıcımız olarak, birçok farklı coğrafi bölgede ve veri merkezinde GPU'lara sahip olan Microsoft Azure'u kullanıyoruz. Sonuç olarak, kendimizi kısa sürede dünyanın dört bir yanındaki birçok bölgede bulduk.
İlk günden itibaren, küçük ekibimiz çok bölgeli, çok kümeli ve küresel olarak dağıtılmış olmak zorundaydı. Kubernetes kümelerimiz çok hızlı bir şekilde evcil hayvan muamelesi görmekten çıkıp sığıra dönüştü.
İyi dengelenmiş bir GPU filosu, yakındaki GPU'ları tahsis etmekten daha önemli bir öncelik haline geldi. ChatGPT için yanıt süresindeki en büyük darboğaz, GPU'ların her seferinde bir jetonu ne kadar hızlı yayınlayabildiğidir. Bu, son kullanıcılara coğrafi olarak daha yakın GPU'ların daha az öncelikli olduğu anlamına geliyor çünkü bir ağ talebinin gidiş-dönüş süresi, GPU'ların "kullanıma hazır" olmasından daha az önemli. Kariyerim bana gecikme nedeniyle uçta bilgi işlem yapmanın önemini öğretti. Bu, özellikle GPU'lar bu kadar kısıtlıyken, bu iş yükleri için daha az alakalı hale geldi.
Zorluk #5: Otomatik ölçeklendirme yetersizliği
Son ve baskın bir zorluk da GPU filomuzu ölçeklendiremememizdi. Satın alınacak veya kiralanacak daha fazla GPU ve dolayısıyla otomatik ölçeklendirilecek GPU yok. GPU edinmenin zorluğu bugün de devam ediyor ve hafifleme belirtisi göstermiyor. Talebin üssü şu anda arzın üssünden daha büyük görünüyor. Sadece daha fazla kullanıcı olmakla kalmıyor, aynı zamanda daha büyük modeller daha fazla işlem gerektiriyor ve aracılar gibi yeni teknikler kullanıcı başına önemli ölçüde daha fazla işlem gerektiriyor.
Gergely'nin notu: Kısa süre önce Meta'nın 2024 sonuna kadar 350.000 NVIDIA H100 GPU için 7-9 milyar dolar harcama taahhüdünü haberleştirdik - küresel arzın yaklaşık %15'i!
Yani, ChatGPT'den "Kapasitemiz doldu" mesajını gördüyseniz, bu doğru bir ifadeydi! Bu, o sırada tüm GPU'larımızı kullandığımız için ölçeklendirecek hiçbir yerimiz olmadığı anlamına geliyordu.
Ne yazık ki, GPT-4 gibi modeller o kadar çok işlem gerektiriyor ki, hizmetimizi geniş ölçekte sunabilmek için şu anda tek seçeneğimiz GPU'lar. Düz CPU'lar büyüklük sırasına göre daha yavaş olacaktır.
5. Çıkarılan Dersler
ChatGPT'yi ölçeklendirmek kesinlikle ortalama bir yazılım mühendisliği ölçeklendirme sorunu değildir. Bununla birlikte, mühendislik ölçeklendirmesi konusunda hızlandırılmış bir kurs oldu ve diğer durumlarda uygulanabilecek pek çok şey öğrendik. İşte öğrendiğimiz temel dersler.
Erken ölçeklendirmede hem orman hem de ağaçlar önemlidir. KV önbellek optimizasyonu ve CUDA çekirdekleri gibi düşük seviyeli ayrıntılar (ağaçlar), küresel veri merkezi stratejisi gibi daha yüksek seviyeli sistem ayrıntıları (orman) kadar önemliydi. Ekibimizin GPU'ların en alt seviyelerinden ürün kararlarına kadar yığın boyunca atlama yeteneği kritik önem taşıyordu.
Sisteminizin kısıtlamalarını uyarlanabilir bir şekilde dikkate alın. OpenAI'ye katılmadan önce aşağıdaki gibi şeyler yapmaya alışkındım:
Genelde "iyi" olarak kabul edilen yaklaşık %80 CPU kullanım metriklerine ulaşmak için sistemleri ayarlamak. Bu metriğe ulaşıldığında, metrik sabit kalırken arkanıza yaslanın.
"Sonsuz büyüklükte" bir buluta otomatik ölçeklendirme; yani her zaman daha fazla makine sağlanabilir.
Uç bilişime öncelik verin: gidiş-dönüş isteklerinin gecikme süresini azaltmak ve kullanıcı deneyimini iyileştirmek için kullanıcıların bulunduğu yere çok yaklaştırın.
OpenAI'de bu uygulamaların hiçbiri geçerli değildi! Hem ölçümü hem de ölçeklendirmesi pratik olan yeni yaklaşımlar bulmamız gerekiyordu.
Ve tam işe yarayan bir şey bulduğumuzda, bir model mimarisi değişecek veya yeni bir çıkarım fikri önerilecek ya da ürün kararları sistemin kullanımını değiştirecekti. Bu yüzden tekrar tekrar adapte olmamız gerekiyordu.
Derinlere dalın. Faaliyet gösterdiğimiz sorun alanında, en düşük seviyeli uygulama ayrıntıları gerçekten önemlidir. ChatGPT'yi metni girdi olarak alan ve diğer uçtan biraz daha akıllı bir metin çıkaran bir "kara kutu" olarak düşünmek cazip geliyor. Ancak, insanlar "kara kutunun" tam olarak nasıl çalıştığına dair en küçük ayrıntılara daldıkça, bir ekip ve ürün olarak daha iyi hale geldik.
Henüz çok erken. Zorlukların ölçeği sadece büyüyecek. GPT-2, 3 ve 4 arasındaki her sıçramada, modelleri ölçekli olarak eğitmek ve çalıştırmak için tamamen yeni yollara ihtiyacımız oldu. Bu gelecek sürümlerde de devam edecek. Görme, görüntü ve konuşma gibi tüm yeni modalitelerimiz, yeni kullanım alanlarının kilidini açarken sistemlerin yeniden tasarlanmasını gerektiriyor.
OpenAI'deki - ve bir bütün olarak ekosistemdeki - gelişimin hızı artıyor. Bir sonraki 10 kat ölçeğin ne gibi zorluklar getireceğini göreceğiz!
Çıkarımlar
Ben yine Gergely.
ChatGPT'yi ölçeklendirmenin zorlukları hakkındaki perdeyi araladığı ve ChatGPT'nin nasıl çalıştığına dair genel bir bakış sunduğu için Evan'a teşekkürler. İşte Evan'ın makalesinden çıkardığım sonuçlar:
ChatGPT'nin nasıl çalıştığı sihirli bir şey değil ve anlaşılmaya değer. Çoğu insan gibi benim de ChatGPT'yi denerken verdiğim ilk tepki sihirli bir şeymiş gibi hissetmem oldu. Soruları yazdım ve bir insandan gelebilecekmiş gibi hissettiren yanıtlar aldım! ChatGPT insan diliyle etkileyici bir şekilde iyi çalışıyor ve herhangi bir insanın başa çıkabileceğinden daha fazla bilgiye erişebiliyor. Programlama ile ilgili sorularda da iyi ve ChatGPT'nin insanlardan daha yetenekli olup olamayacağını sorguladığım bir nokta vardı, programlama gibi insanların şimdiye kadar daha iyi yaptığı alanlarda bile?
ChatGPT'nin sınırlarını anlamak için nasıl çalıştığını anlamanız gerekir. ChatGPT ve diğer LLM'ler insanlar gibi "düşünmez" ve "anlamaz". Bununla birlikte ChatGPT, girdiye ve o ana kadar üretilen her şeye bakarak bir sonraki en olası kelimenin ne olması gerektiğine dayalı olarak kelimeler üretir.
Uzman arama motoru WolframAlpha'nın yaratıcısı Stephen Wolfram, ChatGPT'nin nasıl çalıştığına dair mükemmel bir derinlemesine incelemede ChatGPT'yi özetliyor:
"ChatGPT'nin temel konsepti bir düzeyde oldukça basittir. Web'den, kitaplardan vb. insan eliyle oluşturulmuş büyük bir metin örneğinden başlayın. Ardından bir sinir ağını "bunun gibi" metinler üretmesi için eğitin. Ve özellikle, bir "komut isteminden" başlayabilmesini ve ardından "eğitildiği gibi" bir metinle devam edebilmesini sağlayın.
Gördüğümüz gibi, ChatGPT'deki gerçek sinir ağı çok basit öğelerden oluşuyor - milyarlarca olmasına rağmen. Ve sinir ağının temel işleyişi de çok basittir, esasen şimdiye kadar ürettiği metinden türetilen girdiyi, ürettiği her yeni kelime (veya bir kelimenin bir kısmı) için "öğelerinden bir kez" (herhangi bir döngü vb. olmadan) geçirmekten ibarettir.
Ancak dikkat çekici ve beklenmedik olan şey, bu sürecin web'de, kitaplarda vs. bulunanlara başarılı bir şekilde "benzeyen" metinler üretebilmesidir (...)
ChatGPT'nin özel mühendisliği onu oldukça cazip hale getirmiştir. Ancak nihayetinde (en azından dış araçları kullanana kadar) ChatGPT "sadece" biriktirdiği "geleneksel bilgelik istatistiklerinden" bazı "tutarlı metin dizilerini" çekip çıkarıyor. Ancak sonuçların bu kadar insana benzer olması şaşırtıcı."
ChatGPT'yi ölçeklendirmenin mühendislik zorlukları birbiriyle ilişkilendirilebilir. Bir sistemi ölçeklendirirken, bunlar yaygın olarak kullanılan tekniklerdir:
Tekrarlanan, pahalı hesaplama işlemleri için bellek takası yaparak (ezberleme) veya tam tersini yaparak performansı artırmak; bellek azsa ve kullanılmayan çok sayıda hesaplama varsa bellekten tasarruf etmek için hesaplama kullanmak
Yatay ölçeklendirmek için daha fazla donanım satın alın
Ölçülecek doğru şeyleri belirleyin ve bu metriklerin doğru yönde eğilim göstermesi için iyileştirmeler yapın; durulayın ve tekrarlayın
OpenAI'deki mühendislik ekibi ürünü ölçeklendirmek için tüm bu teknikleri kullandı.
Bazı ölçeklendirme zorlukları bir matematik problemini çözmeye indirgenebilir. Zorluk #2'de - yığın boyutu için optimizasyon - maksimum kullanım için çözüm, işlem sayısını en üst düzeye çıkarırken aynı zamanda bellek bant genişliğini beklememeye geldi. İşlemler ve bellek bant genişliği değerlerini bildiğinizde bu bir optimizasyon alıştırması haline gelir.
Verimliliği optimize etme zorluğuyla karşı karşıya kaldığınızda, bu yaklaşımdan ilham alın. Sisteminizin özelliklerini - verim, gecikme, CPU kullanımı, bellek kullanımı ve diğer ilgili değerler - belirleyin ve birini değiştirmenin diğerini nasıl değiştireceğini bulun. Daha yüksek CPU kullanımı (daha az makine kullanarak) ne anlama gelir? Her makineye bellek eklemek ya da çıkarmak ne anlama gelir? Ve benzeri.
OpenAI bile GPU donanımına kaynak bulmakta zorlanıyor. Büyük dil modelleri büyük miktarlarda işlem gerektirir ve GPU çipleri bu kullanım durumu için en uygun olanlardır. Bugün, NVIDIA'nın yüksek performanslı bir GPU olan H100'ü, yapay zekaya büyük yatırım yapan çoğu şirketin tercih ettiği donanımdır.
H100'lere olan talep, özellikle Meta gibi şirketlerin bunları tedarik etmek için göz kamaştırıcı meblağlar harcamasıyla arzı geride bırakıyor. Kısa süre önce Meta'nın 2024 yılı sonuna kadar 350.000 H100 ünitesine sahip olmak istediğinden bahsetmiştik.
Microsoft ile güçlü ortaklığına ve büyük miktarlarda fon sağlamasına rağmen OpenAI'nin de yeterli GPU bulma sorunu var.
NVIDIA'nın bu talepten büyük ölçüde kâr etmesi bekleniyor, ancak diğer oyuncuların da bu konuda adım atmasını ve rekabet edebilecek çipler tasarlamasını bekleyebiliriz. Nitekim Meta, AWS gibi kendi özel yapay zeka çiplerini oluşturuyor. Büyük çip üreticileri de boş durmuyor: AMD Aralık 2023'te MI300X işlemcisini piyasaya sürdü ve ilk kıyaslamalar H100'den daha iyi performans gösteriyor. Intel, H100'e rakip olması ve onu geçmesi beklenen Gaudi3 işlemcisi üzerinde çalışıyor ve işlemcinin 2024'te piyasaya sürülmesi bekleniyor.
Yine de, yeni GPU'lar piyasaya çıksa bile, seri üretime geçmek daha fazla zaman alacaktır. Yapay zeka alanındaki şirketler önümüzdeki bir ya da iki yıl boyunca GPU kıtlığı yaşayabilir.
Donanım kıtlığıyla ilgili mühendislik zorlukları, akıllıca geçici çözümlere yol açma eğilimindedir. Günümüzde çok az yazılım mühendisi donanım kıtlığına aşinadır çünkü bulut sağlayıcıları sayesinde işlem veya depolama kapasitesi sıkıntısı yoktur. Daha fazla CPU ya da depolama alanına ihtiyaç duyulduğunda, kapasitenin mevcut olup olmadığı değil, ne kadara mal olacağı sorulur.
Aynı zamanda, sektör genelinde donanım kıtlığının yarattığı zorlukları daha önce de gördük. Bu tür kısıtlamalar mühendisleri akıllıca verimlilik kazanımları bulmaya itiyor. Örneğin sanallaştırma, Modern arka uç uygulamalarının geçmişi ve geleceği bölümünde ele aldığımız gibi, donanım kaynaklarını daha iyi kullanma çabalarından doğdu.
OpenAI gibi şirketler tarafından zorunluluktan doğan ve daha sofistike yapay zeka uygulamaları için bile daha düşük bilgi işlem ihtiyaçlarıyla sonuçlanan daha akıllıca geçici çözümler görmeyi umuyorum. Uygulamalı YZ uygulamalarının getireceği gelecek konusunda heyecanlıyım, ancak pratik YZ uygulamalarının, mevcut bilgi işlem altyapısından yüzlerce kat daha fazla enerji tüketen bilgi işlem altyapısı gerektirmemesini umuyorum. Bilgisayarlar, nispeten az enerjiyle çok iş yapan verimli makinelerdir. Daha iyi, daha yetenekli YZ uygulamaları oluşturma yarışı devam ederken bile bu şekilde kalmasını umuyoruz.
✒️ Bu yazı Scaling ChatGPT: Five Real-World Engineering Challenges başlıklı yazıdan çevrilmiştir.